Serverless Data Pipeline - SEC Insider Trades (Form 4)

Introduction
In this post we will demo the design of a serverless data pipeline with aws using SEC Insider Trade (Form 4) data as an example, which is public available.
This post is part of the implementation of Systematic Trading Done Serverless Series.
Securities and Exchange Commission, SEC, is a government agency mainly to enforce law against security market manipulation1.
With Form 4 filing, the public is made aware of the insider’s various transactions in company securities, including the amount purchased or sold and the price per share. An “insider” is an officer, director, 10% stockholder and anyone who possesses inside information because of his or her relationship with the Company or with an officer, director or principal stockholder of the Company.
Form 4 must be filed within two business days following the transaction date. More details check here.
The form is delivered as XML file, for example a form 4 for AAPL and here is the same from in HTML format. Screenshot as below2:

Basically, Form 4 discloses insider’s transactions of the company stocks or derivatives. The information we care is that:
- Who traded, i.e. is he/she a director or officer or 10% owner?
- How many shares at what price?
- When traded, When reported?
- Transaction type: directly trade? Option exercise?
- Buy or Sell?
The goal is: give a universe of companies (identified by SEC id CIK), check
if there are any new Form 4 filings uploaded, if so download the XML files and
extract the insider trade information, then persist them for later usage. It would
also be good that we can get some form of notification if new insider trade happened.
Design Decisions
Here we break the design decision to following parts:
- Decision 1: How will the system scale up?
- Decision 2: Pick up tools from each categories of the services
- Decision 3: Use queue and lambda to achieve parallelization
- Decision 4: What kind of storage should we use to store information
- Decision 5: Design error path as normal path, let exception throw loudly
Here is a diagram of the design in high level:
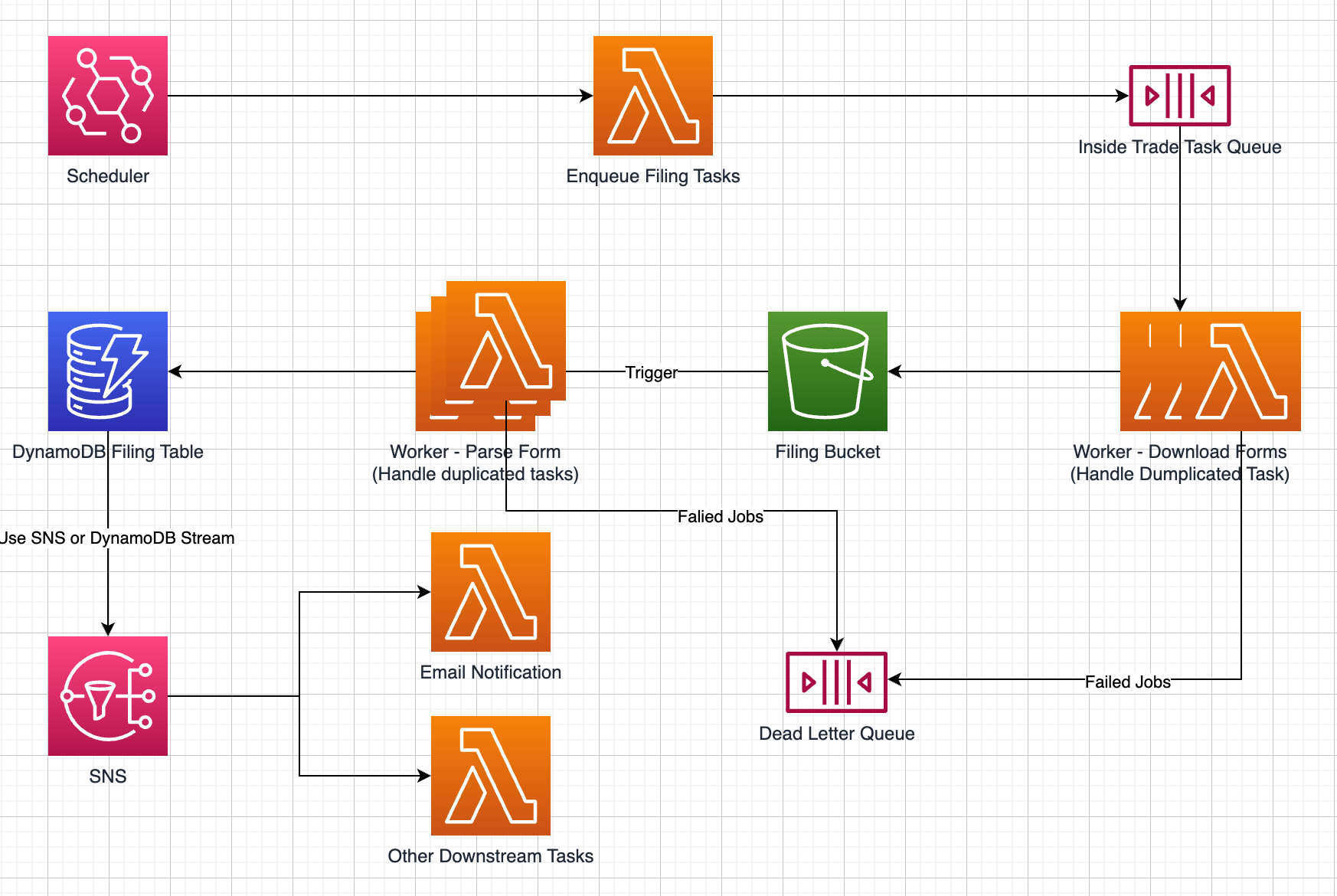
Let’s break it down.
How the Pipeline Scales
Decision 1: Following id based parallelization patterns.
In systematic trading world, nearly every predictor/signal starts with a data pipeline. Most of the data pipelines are name by name basis, meaning given a company or entity, there are multiple fields related to it.
For example, Apple Inc., we have price data, order book data, fundamental data, alternative data such as social media, search activity, event data.
As we can see there are two dimensions about the data: identifier and field. It is not entirely true, we also have a time dimension!
- id,
N - field,
F - time,
T
The next question to ask is: in which dimension we process the data? The objective function is speed, ie how can we process the data in the fastest way? I think the answer drills down to how well we parallelize our data pipeline.
We can parallelize by id, by field, or event by time! Which one should we choose?
It depends on which one is larger and more uniform. Time is not a good choice in
my opinion as time is not even for all the ids and fields. And most of the time,
the number of ids, N, is much larger than the number of fields, F. In this
case, it is better to build the data pipeline by id basis, so that we gain the
most ability to parallelize.
In the end, the decision is we use company names as our parallelization path.
Serverless Data Pipeline
Decision 2: Pick up tools from each categories of the services
In the previous posts, we went through quite a few serverless tools. How to build data pipeline with to serverless tools? As I proposed before, in serverless land, we think in three components, computation, communication, adn storage:
- Computation
- Lambda, for io requests, parsing the file and extracting information
- Communication
- EventBridge, for scheduling
- SQS, for task management
- Storage
- S3, for file storage
- DynamoDB, for post-processed data query
Parallelization
Decision 3: Use queue and lambda to achieve parallelization
Since companies filings are independent, we can parallelize the pipeline very well using lambda and queue.
This is a common design pattern in serverless land, namely queue-lambda.
The idea is the have a daily scheduled job kick off to enqueue all company names, ie the universe we care. After all the jobs are in the queue, we define a lambda function to check and download filing files if any. The benefit of lambda is that we can nearly parallelize every names.
The benefit of a queue-lambda structure is that we can control our parallelization
via lambda’s reserved concurrency. For example, if we set the reserved concurrency to
10, we will not processing more than 10 names at the same time.
There is another subtile yet interesting benefit of lambda: every code start lambda instance has a different public IP address! This is really a great feature in terms scaping type data pipeline. As we probably all know that most of the public available data source have some sort of throttling control. Say for example the SEC website has a rate limit of 10 requests per second. With the different lambda instance with different IPs, we actually increase the limit!
(please… don’t do anything bad with this ….)
I did some experiments to prove this, here is the calling history of a lambda function. The function is easy simply print its IP address:
@2023-02-01 20:00 {"ip": "18.170.55.26"}
@2023-02-01 23:30 {"ip": "18.169.190.4"}
@2023-02-01 23:48 {"ip": "18.134.99.111"}
@2023-02-02 11:17 {"ip": "3.8.162.74"}
@2023-02-02 20:39 {"ip": "18.168.205.156"}
@2023-02-02 22:04 {"ip": "13.42.48.110"}
It turns out, we can get quite a few of public IP address for free with lambda.
SQL or NoSQL or S3
Decision 4: What kind of storage should we use to store information
In this pipeline, there are two pieces of information I would like to keep: the raw Form 4 and processed Form 4. Raw data is just the file we download from SEC website. The processed data is bit more interesting. I only picked following fields:
res = {
"owner": owner,
"cik": cik,
"name": name,
"symbol": symbol,
"tx_date": tx_date,
"tx_code": tx_code,
"tx_side": tx_side,
"tx_shares": tx_shares,
"post_tx_amount": post_tx_amount,
"access_number": access_number,
"filing_date": filing_date,
}
As long as we persist the raw data files, it is always possible to add another downstream jobs to produced another set of post-process information.
Next question is: where shall we store the data?
Raw Data
For the raw data, it is obvious that S3 is the place to go! The interesting part is how can we design the folder and file name.
I proposed following: {BUCKET}/{CIK}/{From}/{FilingDate}#{AccessNumber}.txt.
Although this pipeline only focus on Form 4, I still add a sub path {From} to identify potential more filing forms in the future.
Processed Data
Processed data is almost like a dict in Python, it is highly structured (more structural then XML? Not sure.). And it is a timeseries data by nature.
We have few options here: S3, DynamoDB (No-SQL), and SQL.
S3 seems not very good as lack of query abilities out of box. We could use is as a underlying file system and build a query layer on top, but it sounds to much and we have better options.
I indeed hesitate about DynamoBD and SQL (Serverless version AWS RDS - A relational database). For DynamoDB is THE goto serverless database on aws, it is highly scalable and easy to setup. The tricky bit is the primary key and secondary index design, see details.
On the other hand, RDS a SQL database can never go wrong, right?? Tables, Primary key, foreign key, on top all of these, we have powerful query planner, we can do all sort of join, aggregation on the fly.
Let’s have a look at our data again. It is simple, a key value pair. Let’s say we have 2000 names, 1 files per day. The amount of the data is still very small. Both DynamoDB and RDS fit our purpose. How to select?
The answer is a bit surprise: cost.

With our data, DynamoDB is FREE to use.
So the decision is DynamoDB!
Error Handling
Decision 5: Design error path as normal path, let exception throw loudly
In our data pipeline there are two potential failure points:
- Filing download job
- Filing processing job
The download job is a web io job, it could fail for all sort of reasons, limit cap, network error, etc. The processing job could fail as well, for example, a change XML structure could just fail our parser.
We have to things to handle failures: retry and dead-letter queue.
We could config lambda function to retry 2 time, after all of them failed, the job will be pushed into a dead-letter queue, which will trigger downstream notification to alert the failures.
Notification
Notification on aws is SNS. There are two types of notifications: on purpose and on failures.
In this design, we use DynamoDB stream to publish topics to SNS for on purpose notification. Whereas, on failures notification is done with a lambda consume dead-letter queue items, then publish to a failure topic in SNS.
Implementation
Ah wow, it takes some time to reach this point: implementation! Given this post becomes too long to read (I am trying to limit each post under 2000 words), I will leave the details with next post.
Some key points to encourage you keep an eye:
- How to develop serverless data pipeline with AWS SAM?
- How to design the dynamoDB primary key for processed data?
- How to set batch behavior for queue and lambda?
- How S3 can trigger a lambda worker?
- How to handle reentry of the lambda function?
- How to avoid duplicated jobs? (as we know standard SQS is at least once delivery not exact once delivery)
I am also working to release the source code for the implementation as well.
Summary
In this post, we went through the design process of a serverless data pipeline. The example dataset is SEC Insider Trader filing form 4.
We discussed varies design decisions, such as scalability, parallelization, storage, and error handling.
Interestingly, some time cost is also a design perspective in serverless. For example, for this design, if we run about 505 names, it is almost free!
After the SNS topic of filing topic update, we could develop other downstream jobs, for example computing a signal based on insider trade event. Or some aggregation job to transform the post-processed results to other easy to use format.